 Рано или поздно перед вебмастером встает проблема в раширении количества сателлитов и увеличения контента сайтов. В этом может помочь и существенно облегчить жизнь программа, которая предназначена для выкачивания контента из блогов, каталогов статей, веб-порталов, а также его обработки и импорта в популярные КМС. Программа немного сложновата в освоении, но зато позволяет скачивать чистый контент с сайтов (включая изображения) и сохранять его на диск в txt или htm виде.
Рано или поздно перед вебмастером встает проблема в раширении количества сателлитов и увеличения контента сайтов. В этом может помочь и существенно облегчить жизнь программа, которая предназначена для выкачивания контента из блогов, каталогов статей, веб-порталов, а также его обработки и импорта в популярные КМС. Программа немного сложновата в освоении, но зато позволяет скачивать чистый контент с сайтов (включая изображения) и сохранять его на диск в txt или htm виде.
В качестве бонуса для читателей моего блога предлагаю 5% скидку при покупке данной проги у разработчика.
Итак, немного непосредственно о программе:
Системные требования:
- Windows XP;
- Иинтернет канал в 128 и более кбит/с.
Преимущества программы:
- Подходит под 90% сайтов в сети;
- Позволяет скачивать чистый контент (только текст статьи);
- Многопоточная загрузка контента;
- Позволяет сохранять изображения;
- Сохранение контента в txt и htm виде;
- Импорт в популярные CMS + предпубликационная обработка (автокартинки, автометки и прочее);
- Гибкая настройка парсинга.
Минусы программы:
- Для работы с продуктом требуются определенные навыки.
Поддерживаемые CMS:
- Zebrum;
- Zerber;
- Wordpress;
- Satellite-X
- Autoblog-X;
- Импорт по шаблону (подходит почти для всех CMS);
- Создание статических html и php сайтов (с функцией автовставки кодов бирж).
Принцип работы программы заключается в следующем: Программа загружает статьи по прямым ссылкам на них с помощью функции парсинга ссылок со страниц, карты сайта и функции создания списка ссылок по шаблону.
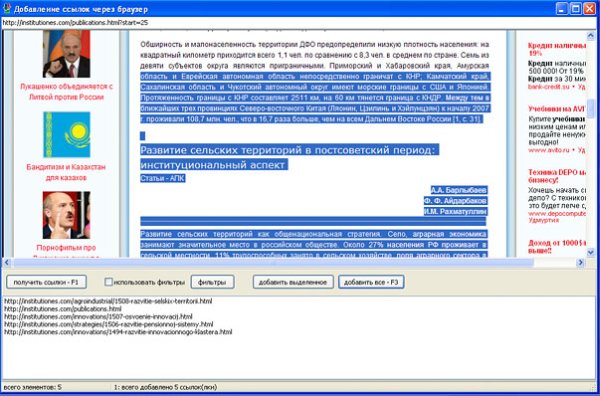 Порядок работы с программой:
Порядок работы с программой:
Парсинг контента
- Открываем программу, идем в настройки, выбираем раздел «ссылки».
- В список ссылок добавляем карту сайта и смотрим, какие ссылки предполагается получить.
- Если страниц слишком много, то задаем границы парсинга. Выделяем ссылку в списке и в опциях задаем границы парсинга.
- После этого настраиваем фильтры.
Вводим стартовый url для сканирования всего сайта и жмём кнопку «получить ссылки». - Удаляем из списка полученных ссылок категории и прочие гадости. Теперь мы имеем только ссылки на статьи.
- Переходим на вкладку «контент», выбираем любую ссылку и задаем границы парсинга для содержимого (начало и конец).
- Ссылаемся для чистоты нашей совести на первоисточник, указываем путь для сохранения и выбираем формат html.
- Включаем загрузку картинок для сохранения в одну папку (кнопка «дополнительно» позволяет указать имя этой папки и выбрать прочие опции).
- Далее настраиваем заголовок. Для этого указываем границы парсинга для заголовка.
- Потом устраиваем предпросмотр любого элемента из списка (двойной клик либо иконка с лупой).
- Если все хорошо, то начинаем парсинг с помощью зелёной двойной стрелочки.
Усе, парсинг закончен, сграбленный контент лежит в нашей папке, идем в эту папку и можно заняться экспортом контента.
Экспорт контента
- Давим на кнопку «Обработка и импорт в КМС» и спомощью расширенной функции добавления файлов добавляем спарсеные файлы.
- Потом выбираем массовую обработку файлов, переходим на вкладку «автозаполнение полей», правим необходимые поля в соответствии с поставленными задачами, меняем заголовки на собственные, добавляем, удаляем все что захотим.
- Так же можно автоматически проставить во все статьи тег < !--more-- > на вкладке «автопростановка тегов».
- В разделе «чистка документов» можно удалить пустые строки в документах.
- На вкладке «преобразование < img >» нужно удалить все префиксы и добавить свой префикс ко всем картинкам.
- Следующий шаг - это закачка спарсенных изображений в нужный каталог вашего сайта.
- Возвращаемся в программу и сохраняем всё, нажав на соответствующую иконку программы, затем приступаем к созданию файла импорта также нажав на соответствующую иконку.
- В открывшемся окне указываем путь для сохранения, необходимую CMS и планируем публикацию на свой фкус и цвет :).
- Давим на кнопку «создать файл импорта» и переходим к импорту материалов на сайт.
Ну а дальше импортируем данный файл через админку используемой вами CMS и радуемся тому что данную замечательную программу Вы приобрели со скидкой 5%.
Оформление покупки:
Цена от Narodlink.ru на Content Downloader: 37 WMZ - 5% (Скидка от Narodlink.ru) = 35,15 WMZ
Цена от Narodlink.ru на Content Downloader: 1147 WMR - 5% (Скидка от Narodlink.ru) = 1089.65 WMR
Перечислите деньги на любой из этих кошельков:
WMR R343596475065
WMZ Z201847902942
В платеже обязательно укажите свой e-mail, наименование программы и наш ID: 077narodlink.ru для получения скидки: Оплата Content Downloader, user@mail.ru, 077narodlink.ru
После оплаты Вы получите письмо с инструкциями, ссылками и паролями для скачивания и установки программы.
Задать любые вопросы по программе вы можете на сайте и форуме разработчика: Content Downloader - программа для парсинга и импорта контента.
Народная ссылка для регистрации:
Content Downloader - программа для парсинга, подготовки и импорта контентаКатегории:
Поделитесь этой записью или добавьте в закладки
Комментариев: 7
Комментировать
Другие материалы и статьи
» Буржуйская биржа ссылок "Link Worth": Итак, представляю буржуйскую биржу ссылок, вернее не просто биржу, а ссылочного брокера с широкими...
» Сервис web-рекламы "Pr rE": Хочу представить сеть веб-рекламы с оплатой за результат и за показы.Сервис осуществялет покупку и прод...
» Яндекс и фильтр АГС-17: В Яндексе подтвердили существование автоматического фильтра - АГС-17Многие вебмастера уже в сентябре по...
» RE:PARK - сервис парковки доменов с неограниченными возможностями: Да, RE:PARK - это настоящая парковка доменов, невиданная ранее!Вы нигде раньше не видели таких возможно...
А есть видео работы проги?
Есть на сайте разработчика
Content Downloader версии 6.91 (25.09.2010):
- Доработана функция рассчета дат в отложенной публикации (теперь даты публикаций статей присваеваются к списку документов не по очереди, а в случайном порядке).
Content Downloader версии 6.89 (25.09.2010):
- Теперь, при парсинге контента, папки с изображениями создаются только к тем документам, где содержатся картинки;
- Теперь количество меток (автозаполнение полей) не фиксированное, а рандомное;
- Исправлены и доработаны функции расстановки дат публикации (при создании файлов импорта в Wordpress, Zebrum);
- Теперь парсятся картинки с пробелами и знаком % в имени файла;
- Множество незначительных нововведений, изменений, исправлений и доработок.
Content Downloader версии 6.87 (23.09.2010):
- Исправлен и доработан инструмент задания границ парсинга;
- Слегка изменен интерфейс вкладки контент;
Проверил по Ашманову сайт jivoymir.ru (в примере приведен), Яндекс -0, GOOGLE -39 стр. А у нас вроде как без яндыкса никуды... Как её использовать, чтобы в яндыкс попасть?
Хотя вот сейчас проверил другие два сайта - оба в яндексе. И ГУгле. Интересная программа.
ссылка вот. *******v.com/computers/programming/parsing/content-downloader/ бесплатно... между прочим.
Между прочим авторские права никто еще не отменял. И гордиться тем, что у вас на сайте лежит пиратская программа не есть хорошо ...